正在加载今日诗词....
📌 Powered by Obsidian Digital Garden and Vercel
载入天数...载入时分秒... 总访问量次 🎉
载入天数...载入时分秒... 总访问量次 🎉
Authors:
Yabo Zhang Yuxiang Wei Dongsheng Jiang Xiaopeng Zhang Wangmeng Zuo Qi Tian
ControlVideo 改编自 ControlNet,采用完全跨帧交互(fully cross-frame interaction),保证了外观一致性,同时减少了生成图像的质量下降。其次,交错帧平滑器(interleaved-frame smoother)通过按顺序时间步插值交替帧来消除整个视频的闪烁。最后,分层采样器(hierarchical sampler)单独生成具有整体一致性的短剪辑,以实现长视频合成。
以前的工作通常用稀疏的跨帧机制代替自注意力,例如,所有帧仅关注第一帧。然而,这些机制会增加自注意力模块中 Q和 K之间的差异,导致视频质量和一致性下降。
将文本到图像模型适应视频模型的主要挑战是确保时间一致性。利用 ControlNet 的可控性,运动序列可以提供结构上的粗略一致性。即使使用相同的初始噪声,使用 ControlNet 单独生成所有帧也会导致外观严重不一致。为了保持视频外观连贯,我们将所有视频帧连接成一个“大图像”,以便可以通过帧间交互来共享它们的内容。考虑到 SD 中的自注意力是由外观相似性驱动的,我们建议通过添加基于注意力的完全跨框架交互来增强整体一致性。
为了缓解帧之间的闪烁问题,实现帧与帧之间的平滑过渡,采用交错帧平滑器对去噪过程中的某些步骤中得到的去噪结果
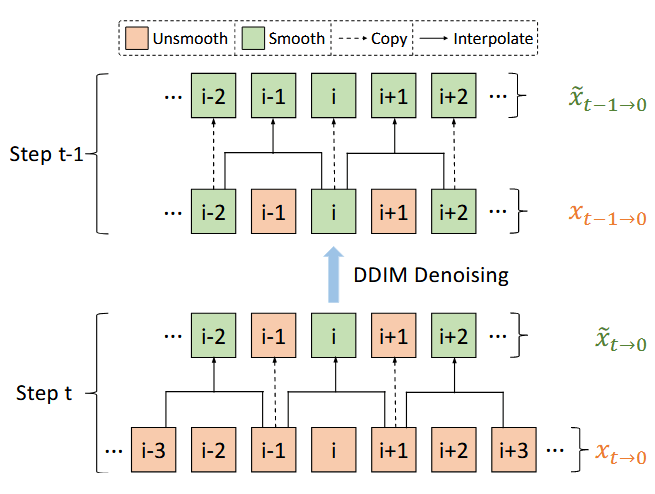
在有限的 GPU 资源和保证视频一致性的前提下,为了生成长视频(100 帧),论文提出了通过分成采样器一块一块地生成长视频。在每个去噪时间步中,根据选择出来的关键帧将长视频序列
关键帧的 attention 为:
视频片段的 attention 为: